機器學習基石筆記 L1–7
(2014–2015年的筆記)
這是臺大資工系林軒田教授在 Coursera 上的機器學習基石 (Machine Learning Foundations) 課程,第 1~7 講的心得筆記,所有的證明過程都不節錄,因為講義中都有。這裡只記錄了自己在學習過程中梳理出來的條理、大綱。對於初學者完全不合適,但如果你已經上過課,卻覺得有點亂、有點迷惑,或許會有一些幫助。

以下所有資料來源都來自于林軒田教授的上課講義。
L1: The Learning Problem
這一講解釋了最基本的 learning flow,也就是 A takes D and H to get g
學習演算法 A 會根據訓練資料集 D 跟 hypothesis set H 去求得 g,然後,我們會很希望 g 能接近真實的 f (target function)

L2: Learning to Answer Yes/No
這一講我們試著去學習怎麼回答一個二元分類的問題,例如,要不要核發信用卡給某位顧客。
針對一個這樣二元分類的問題,他的 H 應該長什麼樣子呢? ⇒這邊用了 Perceptron,一種 linear (binary) classifiers
這其中不同的 w 跟不同的 threshold 會造就不同的 h,組合起來就是一個 H (hypothesis set)
首先,先來看一下在 2D 中的 Perceptrons,在這裡,H = all possible perceptrons (也就是二維上所有的直線)
那如何從這一個 H 中挑出一個理想的 h 當作 g 呢? ⇒ 用 PLA (Perceptron Learning Algo)
演算法的部分就請參照投影片。
這邊關於 PLA 有幾個問題:
(1) PLA 一定會停下來嗎?
(2) 就算 PLA 會停下來,求得的這個 g 跟 f 真的接近嗎? ⇒ L4 會利用機率來討論這件事。
(3) PLA 求得的 g 在 D 以外的資料的表現如何呢?
(4) 如果 PLA 停不下來,那又如何?
首先,先來看 PLA 會不會停下來的問題:
如果他會停下來,我們可以說這個 D 是線性可分的 (linear separable)。
PLA halt ⇒ linear separable
那如果這個 D 是線性可分,他就一定會停嗎?
PLA halt <=?= linear separable
這邊的答案是 Yes
關於 PLA 有兩個特點:
(1) Wt gets more aligned with Wf:也就是 Wt 會愈來愈接近 Wf (如果線性可分的話,必定存在這個 Wf,只是我們找不找得到),這邊是用內積之後愈來愈大來判斷的。當然,內積愈來愈大有可能是因為長度變長,而不只是角度接近。
(2) Wt does not grow too fast:這個特點是來自於 PLA 只有針對有錯的點才會進行修正,根據這個特點,我們知道 Wt 會長得很慢 (長度變化得很慢)。
由 (1), (2) 可知,只要 D 是線性可分的,那 PLA 就會停下來 ⇒ 找得到 Wf ⇒ 把這個 Wf 的 h 當成 g ⇒ 可以從 training examples 中找到 g
(線性不可分先不討論,原本就已經線性不可分,PLA跑到死也找不出那條線,因為根本就沒有那條線…)
PLA 這個演算法的優點是快速、簡單、任何維度都能使用。
缺點是我們無法事先知道 D 是否線性可分,就算假設 D 線性可分,我們也不知道 PLA 多久會停…
再把 noise 考慮進來,要求的東西就變成:

這是一個已知的 NP-hard 的題目…
因此,我們只能修正 PLA 來取得一個 approximately good g ⇒ Pocket PLA (by keeping best weights in pocket)。
L3: Types of Learning
這講沒什麼,就是講一下各種不同類型的學習
L4: Feasibility of Learning
這講是討論學習的可行性。
在第二講,在 D 線性可分的情況下,我們可以學得 g。但問題是,這個在 training examples 中表現很好 (Ein很小) 的 g,真的有接近 f 嗎? 在 out-of-sample 中的他依然可以表現得很好嗎?
在這一講中,引入機率的概念來幫助 ML,機率中有一個 Hoeffding’s Inequality 告訴我們,當 N 夠大時,v (抽樣) 與 u (真正資料的機率) 相差很遠的機率很小。
放進學習中就是:
for any fixed h, in big data (N large), in-sample error Ein(h) is probably close to out-of-sample error Eout(h) within ε.
(在 Hoeffding’s Inequality,我們不需要知道 Eout, f 跟 P 也不用知道。)
但這裡,只討論了一個 h,通常在這種沒有選擇的情況下,h 表現都不會太好。
(試想一下,跑 PLA 時,不修正,就隨便抓一條線,運氣應該不會好到這麼好,隨便抓一條表現就很好。)
如果要讓 Algo 有選擇,那就要有多個 h,不過有多個選擇時,BAD Sample (Ein 跟 Eout 離很遠) 的情況也會惡化。
根據講義,最後求得的是
P[BAD D] ≤ 2 * M * exp(-2 e² N)
這裡的 M 是 hypothesis set H 的大小
所以我們可以這樣說:if |H| = M finite, N large enough, for whatever g picked by A, Eout(g) 會近似 Ein(g)
那如果可以找出 Ein 很小的 h 來當 g: if A finds one g with small Ein(g), PAC guarantee for small Eout(g)
簡單的說就是在 M 有限,N 夠大時,Ein 跟 Eout 會很接近,這時候你找得到很小的 Ein,也就保證了 Eout 可以很小 ⇒ 在真正的資料上,表現得也很好,回答了這一講一開始問的問題。
L5: Training vs Testing
上一講的結論中有一個條件是 M 要有限,但光是我們的 2D Perceptron 的 M 就已經是無限的了,那 2D Perceptron 到底能不能學?
(復習:2D perceptron 中的 H 是平面中所有的線,所以是無限多個。)
(復習:PLA 可以找到 Ein 小的,但我們目前還無法保證在 training examples 中表現好的 g,在真正的資料中也能表現得好。)
觀察一下這個式子:P[BAD D] ≤ 2 * M * exp(-2 e² N)
其中的 M 如果是無限大的話,那不就表示,Ein 跟 Eout 很遠的機率很大…
這太慘了,於是我們想要找一個“有限”的數值來代替這個無限大的 M。
回想一下這個 M 那裡來的,在 L4 推導的過程中,我們是用 union,這太高估了,現在換一種視角來看,從“資料”的角度來看:
平面中有一個點 x1,他的可能性就只有 +1 跟 -1 兩種,這平面上的線仍然無限多條,但管你有幾千、幾萬條,x1 要麻是 +1, 要嘛是 -1,就很單純的只有兩種。
對 2 個點來說,就是只有 oo, ox, xo, xx 四種可能。
對 3 個點來說,只有 6 或 8 種。(跟這三個點的排列方式有關係)
對 4 個點來說,只有 14 種。…
這稱為 effective number of lines,且會 ≤ 2^N
這個數字 effective(N) 是有限的,他能取代無限大的 M 嗎?⇐ 這是我們希望的
不過這個數字會跟點的排列方式有關係,變動太大了。
這邊再引入一個概念 Dichotomies: hypothesis limited to the eyes of x1, x2, …, xN,我們記成 H(x1, x2, …, xN)
總之就是,從資料的視角來看待 hypothesis。
|H(x1, x2, …, xN)| 這個會取決于點的排列方式 (例如 3 個點的時候,可能有 6 種,也可能是 8 種)
growth function: 移除對點排列方式的依賴,找 max 的那組
mH(N) = max |H(x1, x2, …, xN)|
所以在 lines in 2D: mH(3) = max (6,8, …) = 8
講義中舉了幾個例子:
(1) Positive Rays: mH(N) = N + 1
(2) Positive Interval: mH(N) = 0.5N²+0.5N+1
(3) Positive and Negative Rays: mH(N) = 2N
(4) Convex Sets: mH(N) = 2^N ⇒ 這種可以把所有dichotomies可能性做出來的,我們稱為 shatter
(5) 2D Perceptron: 無法歸納,只能知道 mH(N) < 2^N in some cases
那這個 mH(N) 可以取代 M 嗎?
(如果可以的話,我們會很希望 mH(N) 的成長是 poly 的,這樣就可以抵消掉 N 的 exp 成長,只得 Ein 跟 Eout 距離很遠的機率被限制住。)
為了討論 mH(N) 的成長速度,這邊先在引入一個概念: Break point k of H
不能被 shatter 的點的數目,通常只討論 minimun。mH(N) < 2^k
Q: mH(N) 的成長速度會跟這個 k 有關嗎?
L6: Theory of Generation
在L4,我們得到一個結論是: 在 M 有限,N 夠大時,Ein 跟 Eout 會很接近。(這時候你找得到很小的 Ein,也就保證了 Eout 可以很小。)
在L5,我們嘗試討論 M 是無限大的情況,想利用有限的 mH(N) 來取代 M。
在L6 就來討論一下 break point 對 mH(N) 帶來的限制,這邊在引入一個 Bounding Function B(N, K): maximum possible mH(N) when break point k。
引入這個 B(N, K) 是為了去除 H 的影響,只看 K,也就是,即便是不同的 H,只要其 K 是一樣的,那他們的 mH(N) 都一樣被這個 B(N, K) 給限制住。
經過一番推導,得到 mH(N) ≤ B(N, K) ≤ N^(k-1)
例如 2D perceptron 的 k 是 4,那雖然我們不知道他的 mH(N) 的 closed form,但我們可以知道,他的 mH(N) 會被 B(N, 4) 給限制住,而且其成長速度是 O(N^(k-1))。
⇒ 那這樣已經知道 mH(N) 會長得很慢了 (poly)了,那他可以取代 M 嗎?
經過一番辛苦地證明,証出了做一些調整之後,mH(N)可以取代 M。
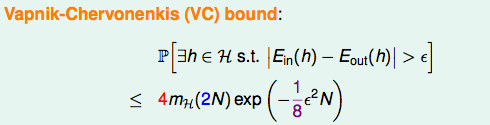
到這裡,我們終於證明了,在 2D perceptron (M 是無限的 case 之一),他的 Ein 跟 Eout 相差很遠的機率很小,又透過 PLA 可以學得 small Ein 的 h 來當 g,因為 Eout(g) 會很接近 Ein(g),所以 Eout(g) 也會很小。 ⇒ 2D perceptron 可以學!!
L7: VC Dimension
L6 證明了 2D Perceptron 可以學,那多維的呢?
為了證明多維度的,引入了 dvc 的概念,dvc 其實就是 maximum non-break point,也就是 k-1。
if N ≥ 2, dvc ≥ 2, mH(N) ≤ N^dvc (這只是把 L6 的結論用 dvc 再寫一次而已。)
finite dvc ⇒ good H ⇒ g will generalize (Eout(g)會近似Ein(g))
於是,如果要證明 d-D perceptron 可學,就要證明他的 dvc 是 finite 的。
經過一番證明,我們求得 d-D perceptron 的 dvc = d + 1,是 finite 的,所以 d 維的 perceptron 也可學!
不過,也不是每個模型都這麼幸運可以輕易地找到 dvc,對於找不到 dvc 的複雜模型來說,我們可以用自由度來近似 dvc。
事實上,這也是 dvc 的物理意義:在 H 做二元分類的情況下,有多少自由度?
dvc(H): powerfulness of H
L7 的最後,回頭討論了 dvc 大小的問題。dvc 本身代表的其實是 model complexity,而 ε 代表的是 Penalty for Model Complexity (Ω(N, H, δ))。如下圖所示,選擇一個好的 dvc 非常重要(也就是一個好的 H),不能只是一昧地追求 Ein 小的,因為是會付出代價的 (Penalty for Model Complexity)。初學者常沈迷於追尋 algo 或是 Ein 小的,而忽略了對 dvc (H 與 D 等) 的考量。
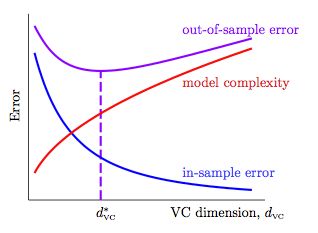
記得,在 training examples 表現好的,在真實的資料上,可不盡然。
